
MLOps
Achieve the greatest possible level of automation.
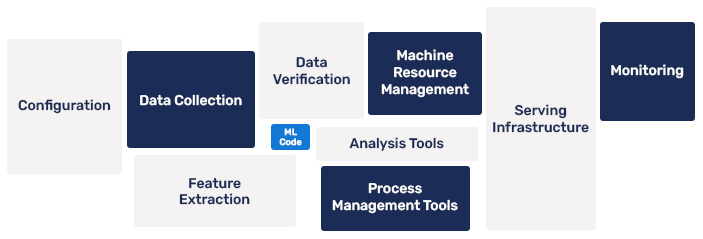
From DevOps to MLOps
DevOps was widely adopted in the past decade for developing, testing, deploying, and operating large-scale conventional software systems. With DevOps, development cycles became shorter, deployment speed increased, and system releases became auditable and dependable.
Moreover, with the advances made in the past few years in ML and AI, Machine Learning (ML) has revolutionized the world of computers by allowing them to learn as they progress forward with large datasets. Thus, mitigating many previous programming pitfalls and creating new possibilities/use-cases that conventional programming cannot resolve. Unfortunately, applying DevOps principles directly to Machine learning development is not possible. Because unlike DevOps where the final product is solely dependent on code.
ML development is code and data dependent. Moreover, ML models’ development is experimental in nature and has more components that are significantly more complex to build and operate. It is worthy to note that the time spent writing ML code is Approx. 30% of the data scientists’ time, the rest is data analysis, feature engineering, experimenting with different hyperparameters, utilizing remote hardware to run multiple experiments in parallel, experiment tracking, model serving, and many more
What is MLOps?
That brings us to MLOps. It was founded at the intersection of DevOps and Machine Learning. Therefore, MLOps is modeled after DevOps. However, it adds data scientists and machine learning engineers to the team. Machine learning operations intend to automate as much as possible, from data sourcing to model monitoring and model re-training.
MLOps abstracts the complex infrastructure (bare metal, virtualized cloud, container orchestration) with diverse hardware (CPU, GPU, TPU) and diverse environment needs – libs, frameworks and provides a set of interoperable tools that accelerates ML Model development in all its phases.
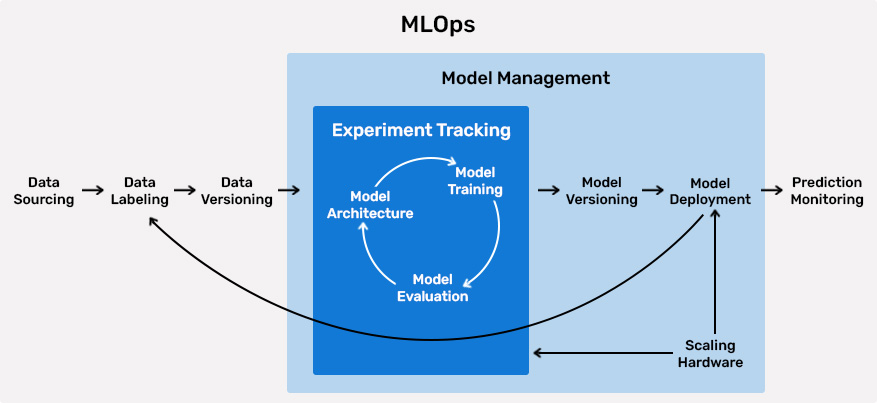
A brief intro into the key phases of MLOps

PHASE 1: DATA GATHERING AND ANALYSIS.
Data gathering is about selecting and integrating relevant data from various data sources, these sources can be databases, data stores, object storage, or streaming data.
Data analysis is about performing exploratory data analysis to understand the available data for building the ML model.
THIS PROCESS LEADS TO THE FOLLOWING:
- Understanding the data schema and characteristics that are expected by the model.
- Identifying the data preparation and feature engineering that are needed for the model.

PHASE 2: DATA LABELING
In machine learning, data labeling is the process of identifying raw data (images, text files, audio, videos, etc.) and adding one or more meaningful labels to provide context so that a machine learning model can learn from it. For example, labels might indicate whether a photo contains a cat or car, which words were uttered in an audio recording, or if an x-ray contains a tumor. Data labeling is required for a variety of use cases including computer vision, natural language processing, and speech recognition.

PHASE 3: MODEL TRAINING, DEVELOPMENT, AND VALIDATION
ML models can be trained via multiple open-source programming libraries. Moreover, training such models usually requires GPU resources that are not easy to share across multiple teams. Therefore, MLOps offers a way to share the GPU resources, a flexible development environment that allows each data scientist to choose his own set of libraries and tools, and since building ML Models is an iterative and experimental process, it offers a way to train multiple models in a parallel/distributed fashion. Finally, it makes sure that the evaluation metrics from each trained model are saved for comparison, and that all the trained models are versioned and available for usage.

PHASE 4: MODEL SERVING
Deployment of machine learning models, or simply, putting models into production, means making the models available to other systems within the organization or the over the internet, so that they can receive streams of data and return predictions.
How the models are deployed into production is what separates an academic ML development from an investment in ML that is value-generating for the business. At scale, this becomes painfully complex. Therefore, an MLOps platform offers a way to serve/deploy ML models so that they can reach the end user faster.

PHASE 5: MODEL MONITORING AND RE-TRAINING
In terms of monitoring our application, we might be worried about system metrics, error rates, traffic volume, app loading times, infrastructure (server counts, load, CPU/GPU usage), things like that. our application scales to a lot of users, and it works as intended and solves the problem it was built to solve. That’s conventional software. But with machine learning it is a bit different. We monitor our models for data distribution changes, training-serving skew, model/concept drift, and outliers. Therefore, a monitoring software is an integral part of an MLOps platform, and it accounts for the external variability that is enforced on our model by the data generated in the real world and it ensures that our models are behaving as they should.
Contact us!
We’re here for you
"*" indicates required fields