Portworx – z czym to się je i po co powstał.

Według szacunków Forrester, na rynku jest obecnie ponad 500 milionów różnych aplikacji Cloud Native. Ta ilość aplikacji stanowi wyzwanie w zakresie utrzymania infrastruktury, zarządzania i ochrony danych. Jednym z wyzwań dla organizacji jest elastyczna migracja i działanie aplikacji między środowiskiem On-premise a Chmurą. Postanowiłem przyjrzeć się jak z radzi sobie z tym zagadnieniem Portworx.
Tak najczęściej wyglądają poszczególne warstwy budowy aplikacji z podziałem:
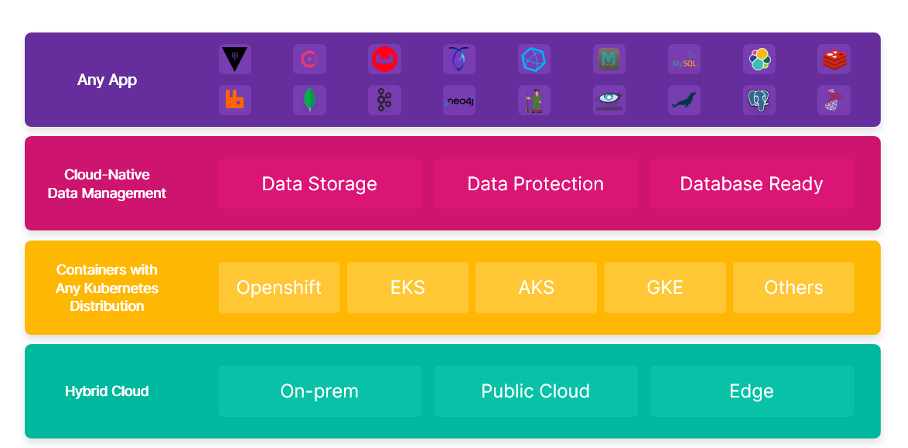
Każda z tych warstw zarządzana jest często przez inny zespół jednak jako całość musi być spójna, gdyż nadrzędnym celem jest dostarczenie aplikacji dla użytkowników w celu realizacji procesów biznesowych.
Warstwy Budowy Aplikacji i Miejsce Portworx
Budowa aplikacji najczęściej jest podzielona na warstwy , z których każda bywa zarządzana przez inny zespół, ale muszą być spójne w celu dostarczenia aplikacji użytkownikom:
- Any App (dowolna aplikacja)
- Cloud-Native Data Management
- Containers with Any Kubernetes Distribution (Kontenery z dowolną dystrybucją Kubernetes)
- Hybrid Cloud (Chmura Hybrydowa) – obejmująca On-prem (lokalnie), Public Cloud (Chmurę Publiczną) i Edge
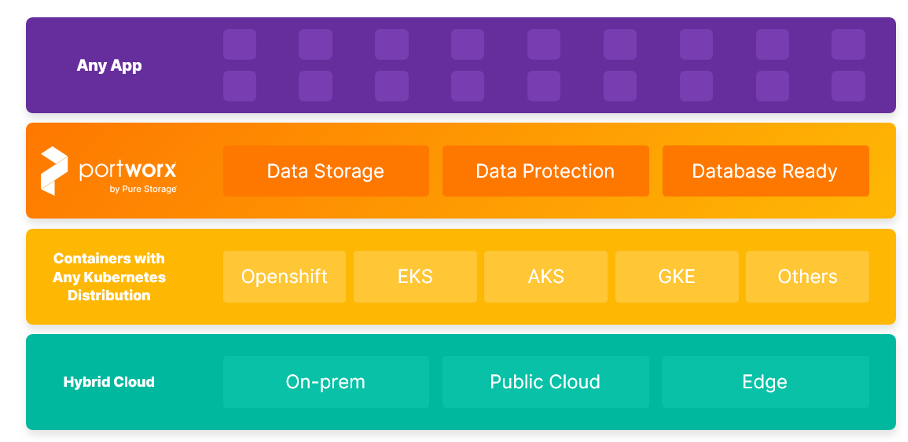
Ten artykuł skupia się na warstwie Cloud-Native Data Management i wyzwaniach z nią związanych.
Rozwiązanie Portworx adresuje obszary w ramach zarządzania danymi Cloud-Native:
- Data Storage (Przechowywanie Danych)
- Data Protection (Ochrona Danych)
- Database Ready (Gotowość Bazy Danych)
🛠️ Modele Licencyjne Portworx
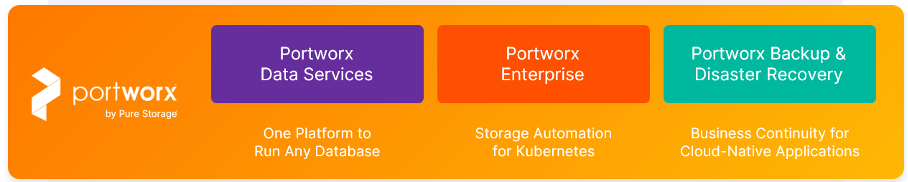
Rozwiązanie Portworx jest dostępne w kilku modelach licencyjnych:
| Model Licencyjny | Cel |
| Portworx Data Services | Jedna platforma do uruchamiania dowolnej bazy danych (One Platform to Run Any Database). Dostarcza gotowe bazy danych (np. Kafka, Cassandra, MongoDB, Postgres, Elastic, MySQL) dla aplikacji kontenerowych. Cały proces jest w pełni zautomatyzowany, nastawiony na szybkie dostarczenie gotowej bazy danych (One-Click DBPaaS). |
| Portworx Enterprise | Automatyzacja przechowywania (Storage Automation) dla Kubernetes. Zapewnia zasoby dyskowe dla aplikacji niezależnie od środowiska oraz wysoką dostępność i wydajność. |
| Portworx Backup & Disaster Recovery | Ciągłość działania (Business Continuity) dla aplikacji Cloud-Native. Zapewnia automatyzację procesów Backup i Disaster Recovery, dostępnych dla operatora w postaci self-portalu. |
Testowanie Portworx Backup & Disaster Recovery
W celu przetestowania możliwości ochrony środowisk K8s wybrano moduł Portworx Backup & Disaster Recovery.
Proces Backupu
- Logowanie i Dashboard: Po zalogowaniu do konsoli Portworx widoczny jest Dashboard z dostępnymi opcjami i widokiem skonfigurowanych klastrów.
- Konfiguracja Polityki Backupu: W zakładce Schedule Policies dodaje się nową politykę, np. uruchamianą co 15 minut.
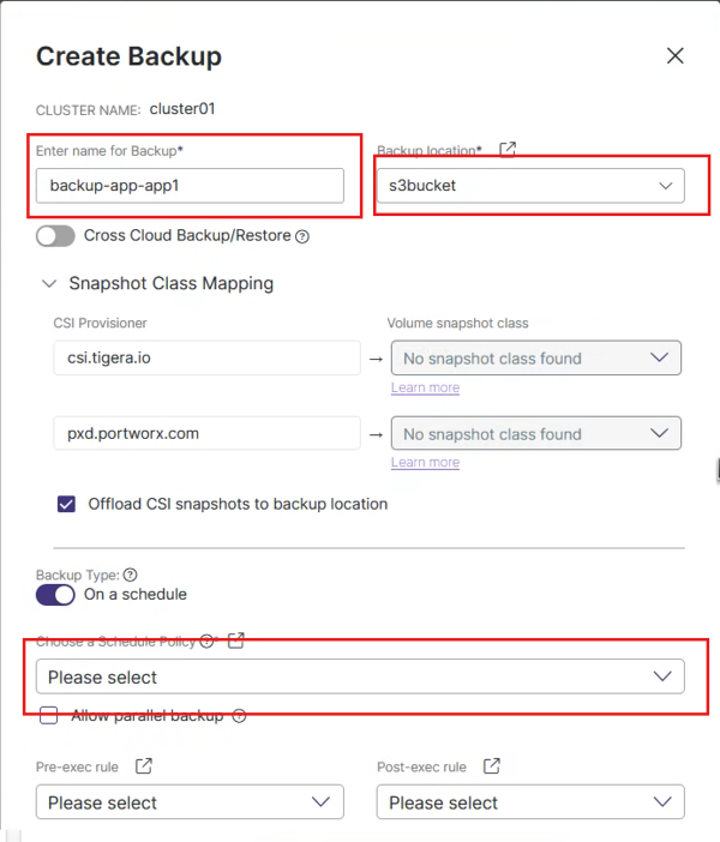
- Tworzenie Zadania Backupu: Przechodząc do widoku klastra (Cluster) i zakładki Applications, zaznacza się odpowiedni namespace (np.
petclinic) i wybiera opcję Backup. - W oknie Create Backup podaje się nazwę, lokalizację (np.
s3bucket) oraz wybiera wcześniej przygotowaną politykę harmonogramu (np. co 15 minut). Można też wybrać akcje do wykonania przed (Pre-exec rule) i po (Post-exec rule) wykonaniu kopii. - Status wykonania kopii bezpieczeństwa widoczny jest w konsoli po kliknięciu na dane zadanie backupu.
Proces Odtwarzania Danych
- Inicjowanie Odtwarzania: Proces przywracania jest intuicyjny. W zakładce All Backups wybiera się kopię zapasową i opcję Restore.
- Opcje Odtwarzania: Otwiera się okno dialogowe, w którym można wybrać Default restore (zgodnie z wcześniejszymi konfiguracjami) lub Custom restore w celu dostosowania procesu do środowiska. Po odtworzeniu można sprawdzić przywrócone obiekty.
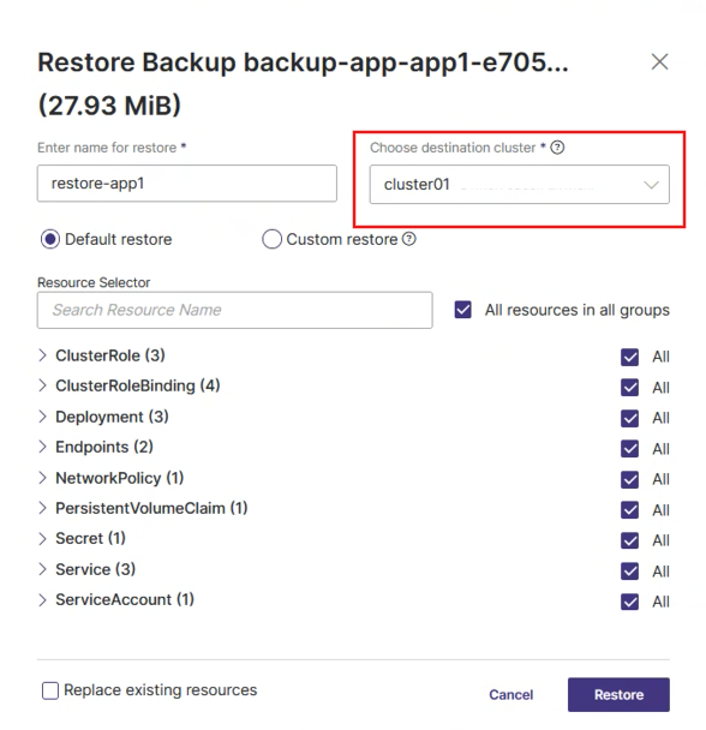
Odtwarzanie na Inny Klaster
Portworx umożliwia odtworzenie środowiska na innym klastrze (DR lub testowym).
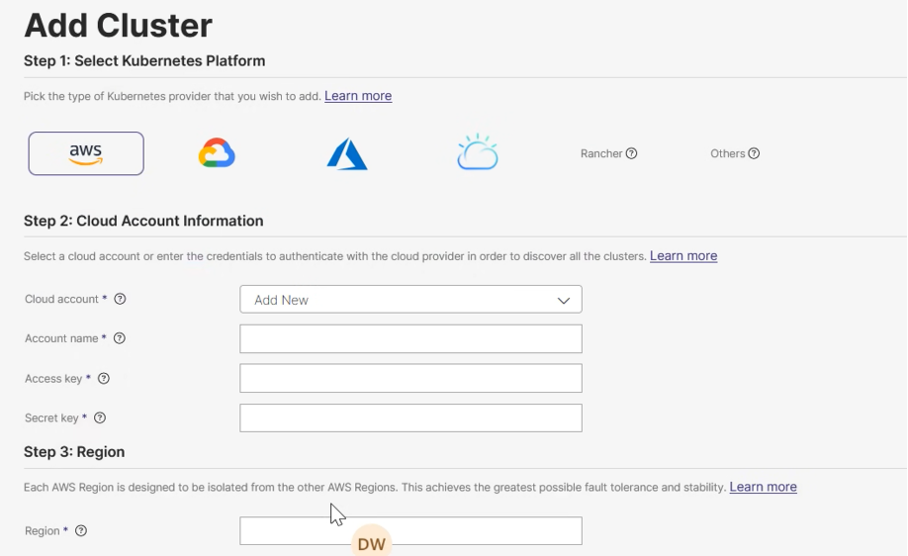
- Dodanie Nowego Klastra: Procedura dodania nowego klastra jest intuicyjna. Wybierając opcję Add Cluster i następnie Others, podaje się nazwę klastra (np.
cluster02) oraz plik konfiguracyjny K8s lub wynik poleceniakubectl config view --flatten --minify. - Odtwarzanie Między Klastrami: W opcji Restore na Cluster 01 wybiera się Cluster 02 jako lokalizację docelową. Można wybrać odtworzenie tylko konkretnej aplikacji z powiązanymi obiektami. Proces można śledzić w zakładce Restore na Cluster 02.
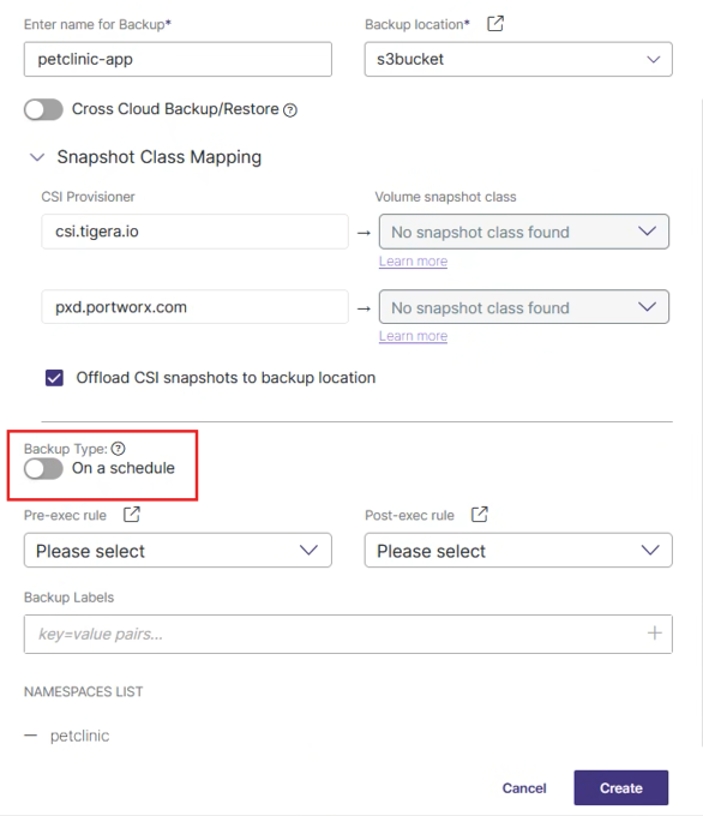
Backup On-Demand i Selekcja Zasobów
- Backup On-Demand (z ręki): Aby wykonać backup bez ustawiania harmonogramu, należy w oknie Create Backup odznaczyć opcję On a schedule i wybrać Create.
- Selekcja Zasobów: Portworx umożliwia wybranie, które dokładnie dane mają być chronione dla danego namespace. Pozwala to na kontrolowanie procesu ochrony na poziomie poszczególnych aplikacji. Możliwe jest np. objęcie kopią wszystkich danych w namespace z wyjątkiem PersistentVolumeClaim (PVC), czyli danych znajdujących się na storage.
Podsumowanie
Portworx to rozwiązanie, które poprzez dodanie warstwy abstrakcji upraszcza cały proces tworzenia, ochrony i zarządzania środowiskiem kontenerowym. Jest to szczególnie interesujące dla budowy środowisk hybrydowych, obejmujących środowiska lokalne (np. OpenShift, Tanzu) i dostawców zewnętrznych (AWS, GKE).
Materiał powstał przy współpracy z Arrow ECS Polska – dystrybutor rozwiązań IT,
w tym Pure Storage – lidera w obszarze innowacji pamięci masowej.

Relevant posts

Ewangelista czy Wojownik? Czym różni się vExpert od tytułu Broadcom Knight?
W ekosystemie technologii VMware istnieją dwa prestiżowe tytuły, które choć brzmią podobnie, pełnią zupełnie inne role. W naszym zespole mamy...

Co dwie nagrody to nie jedna – ale czy to się opłaca?
Tak się złożyło, że marzec przyniósł nam dwa najważniejsze wyróżnienia w ekosystemie VMware: President’s Choice Partner of the Year oraz...

1,2,3, re:Invent w trzech odsłonach
Trzy punkty widzenia oczami trzech uczestniczek. Jedna z nich – po raz pierwszy na wydarzeniu tego typu, druga – jako...

Przyszłość i wyzwania IT cz. 2.
Przyszłość infrastruktury IT rysuje się jako dynamiczna i innowacyjna, odzwierciedlając zmieniający się krajobraz technologiczny. Oto kilka kluczowych trendów, które będą...

Integracja argo-rollouts z traffic splittingiem w ISTIO, cz. 3
Wracamy do naszego cyklu o ISTIO. Opisując integrację argo-rollouts z traffic splittingiem w ISTIO, w 1 cz. został omówiony temat...

Rycerze Broadcom w evoila
Czym są Rycerze Broadcom (Broadcom Knights)? Nie jest przypadkiem, że termin „Rycerz” („Knight”) znajduje się w centrum programu. Podobnie jak...