
MLOps
Den größtmöglichen Grad an Automation erreichen.
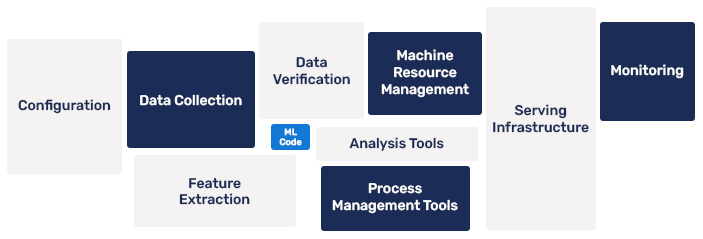
Von DevOps zu MLOps
In den vergangenen zehn Jahren hat sich DevOps in Entwicklung, Testen, Bereitstellung und Betrieb von großen konventionellen Softwaresystemen etabliert. DevOps hat die Entwicklungszyklen beschleunigt, die Bereitstellungsdauer verkürzt und Produktivsysteme wartbar und verlässlich gemacht.
KI und besonders Machine Learning (ML) Anwendungen haben die IT-Welt in den letzten Jahren revolutioniert, indem sie es Computern ermöglichten, aus riesigen Datensets zu lernen. Dadurch konnten Aufgaben gelöst werden, an denen klassische Programme scheiterten und häufige Problem umgangen werden.
Leider können DevOps Prinzipien nicht unmittelbar auf die Entwicklung von ML-Modellen angewendet werden. Dies liegt daran, dass klassische Software rein abhängig vom entwickelten Programmcode ist. ML-Modellen dagegen sind abhängig von den verwendeten Daten. Die verwendeten Konzepte und Einstellungen werden experimentell ausgewählt und optimiert. Dadurch ist die Entwicklung der einzelnen Komponenten deutlich komplexer als in der klassischen Softwareentwicklung. Lediglich etwa 30 % der Entwicklungszeit werden für Implementation verwendet. Der restliche Aufwand liegt in Datenanalyse und Vorbereitung, Experimente mit Konfigurationen, Einsatz von remote Hardware zur parallelen Ausführung mehrerer Experimente, Auswertung der Experimente, Bereitstellung der Modelle und vieles mehr.
Was ist MLOps?
MLOps stellt die an Machine Learning angepassten DevOps Prinzipien dar. Das Ziel ist es, den größtmöglichen Grad an Automation zu erreichen. Durch wiederverwendbare Strukturen und Prozesse können sich die Data Scientists und Data Engineers auf die projektspezifischen Aufgaben konzentrieren. Das automatische Sammeln von Daten, sowie das Monitoring und Aktualisieren der aktiven Modelle vereinfacht die Entwicklung und Wartung von Anwendungen im Betrieb.
MLOps abstrahiert komplexe Infrastruktur (bare metal, Cloud, Virtualisierung, Server-Cluster) mit vielfältiger Hardware (CPU, GPU, TPU) und stellt die Ressourcen zentral bereit.
Es vereinheitlicht den Entwicklungsprozess, ohne die Auswahl der verwendbaren Frameworks und Bibliotheken einzuschränken. Durch die Verbindung einer Vielzahl von Tools wird die Entwicklung in allen Phasen deutlich beschleunigt und optimiert.
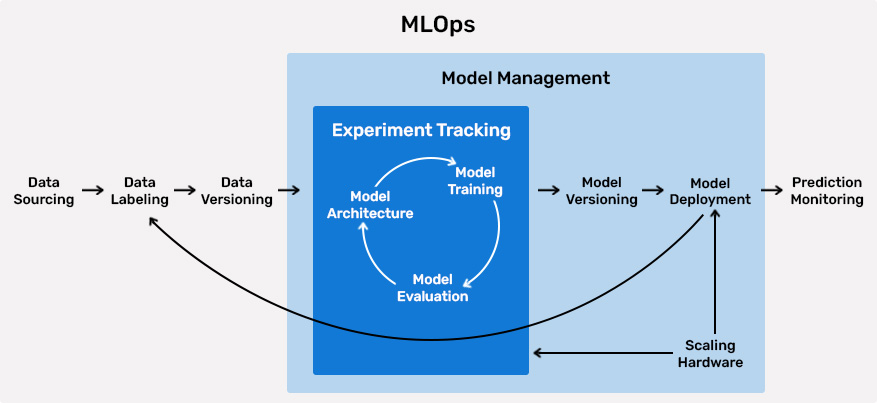
A brief intro into the key phases of MLOps

PHASE 1: DATENSAMMLUNG UND ANALYSE
Relevante Daten werden mit Pipelines aus verschiedensten Datenquellen extrahiert, aufbereitet und zentral gesammelt. Quellen können unter anderem Datenbanken, Objektspeicher oder Streams sein.
In der Analyse werden die Daten statistisch ausgewertet und erforscht, um die wichtigen Zusammenhänge zu erkennen, die für die Entwicklung eines guten ML Modells wichtig sind.
ZIELE DER PHASE SIND:
- Definieren des Datenschemas und der Ausprägungen, die das Modell verarbeiten kann.
- Identifizieren der notwendigen Vorbereitungen und Transformationen vor Eingabe der Daten in das Modell.

PHASE 2: DATEN LABELN
Beim Labeln werden Beispieldatensätze entsprechend der zu lösenden Aufgabe von Menschen erzeugt, mit denen die Modelle die Interpretation erlernen. Ein oder mehrere Label geben, an welche Antwort korrekt für den entsprechenden Datensatz ist. Zum Beispiel, dass ein Bild eine Katze oder ein Auto zeigt, welche Worte in einer Tonaufzeichnung gesprochen wurden oder ob ein Röntgenbild einen Tumor enthält. Daten müssen für eine große Bandbreite an Anwendungsfällen gelabelt werden, zum Beispiel Bilderkennung, Verarbeitung von natürlicher Sprache und Spracherkennung.

PHASE 3: DAS MODELL ENTWICKELN, TRAINIEREN UND VALIDIEREN
Es existieren einige Open-Source Frameworks, mit denen Machine Learning Modelle entwickelt werden können. Das Training der Modelle kann stark durch die Nutzung von GPU-Ressourcen beschleunigt werden, die nicht ohne Weiteres gemeinsam von mehreren Teams effizient genutzt werden können. MLOps ermöglicht es Teams, die gleichen Hardwareressourcen zu verwenden, wodurch eine gleichmäßigere Auslastung erreicht wird. Die Data Scientists können flexibel ihre bevorzugten Tools und Bibliotheken für ihre Experimente einsetzen und mehrere Modelle gleichzeitig und verteilt auf der zentralisierten Hardware trainieren. Die erzeugten Modelle und Messwerte werden gespeichert und können später verglichen und genutzt werden.

PHASE 4: BEREITSTELLUNG DES MODELLS
Durch die Bereitstellung, oder die Überführung ins Produkivsystems, wird das Modell für die Öffentlichkeit oder Intern zugänglich gemacht. Anwendungen, die Daten an das Modell senden, erhalten eine Schätzung als Antwort.
Die Bereitstellung unterscheidet ein akademisches Experiment von einem ML Investment, das ein Businessvalue erzeugt. Besonders bei der Skalierung für Anwendungen mit vielen Nutzern steigt die Komplexität enorm. MLOps reduziert die Komplexität und sorgt für ein einfachere und schnellere Veröffentlichung von Modellen.

PHASE 5: ÜBERWACHUNG UND AKTUALISIERUNG
Um die Qualität der Anwendung zu sichern, werden dauerhaft Messwerte überwacht. Dazu zählen die Systemauslastung, Fehlerraten, Traffic, Berechnungsdauern und Auslastung der Infrastruktur. So kann gewährleistet werden, dass die Anwendung sich an Bedarf anpasst und eine gleichbleibende Nutzererfahrung bietet. Zusätzlich zu diesen klassischen DevOps-Anforderungen muss die Verteilung der Daten, Extremwerte, starke Abweichungen zu den Trainingsdaten und die Genauigkeit überwacht werden. Deswegen ist eine zusätzliche Monitoring Software integraler Bestandteil einer MLOps Plattform. Entscheidende Änderungen in der Außenwelt werden frühzeitig erkannt und gemeldet, bevor ein großer Schaden entstehen kann.
„*“ zeigt erforderliche Felder an